
This article is prepared to show how I take steps to reduce
the top wait events in a busy system running in my environment. As always your
comments and suggestions are welcome so that you and I can learn oracle and
benefited mutually.
For basic tuning steps and some threshold values please
refer to the links below.
These links above give you the basics of performance tuning.
Mind this is very old approach and many things have changed from this approach.
But when speaking about threshold metrics, you can use those individual queries
to check the performance metrics.
For eg.
select 100*(1 -
(v3.value / (v1.value + v2.value))) "Cache Hit Ratio [%]"
from v$sysstat v1, v$sysstat v2, v$sysstat v3
where
v1.name = 'db block gets' and
v2.name = 'consistent gets' and
v3.name = 'physical reads';
from v$sysstat v1, v$sysstat v2, v$sysstat v3
where
v1.name = 'db block gets' and
v2.name = 'consistent gets' and
v3.name = 'physical reads';
The above query is used to
calculate the buffer cache hit ratio and typically it should be very high (more
than 90%)
Ok, coming to the point where
I fine tuned the application is as below.
Scenario: This is an
application where batch jobs of huge amount of data (millions of rows) are
deleted and updated/inserted on a daily basis. Application team reported that
the application is responding very slowly than before as their delete job runs
4~5 folds slower.
While generating the AWR
report at the specified time (the time the delete/insert batch job runs), we
can find the below report portion.
I have got the instance
efficiency percentages as below

You can see from the above that the buffer hit percentage is
nearly 100% and comparatively library hit and soft parse % are good as well. We
can tune the machine to increase the soft parse % here by making either the SGA
to a bigger value or by making use of bind variables (This is an application
where many queries are using bind variables and still the value is low, reason
being cursor_sharing
is set to EXACT
which will not take sql statements which use
bind variables as used statement and takes every statement as new statement).
While generating the AWR report at the specified time (the
time the delete/insert batch job runs), we can find the below report portion.

The Top 5 timed event resulted as above which shows that the
reads are taking time in the system. Hence check with the SQL ordered by Reads
as below.
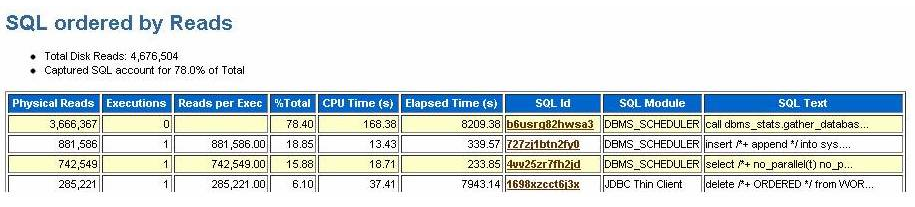
Looking at the statistics from the AWR report, the following
query is consuming more reads.
- call dbms_stats.gather_database_stats_job_proc ( )
- insert /*+ append */ into sys.ora_temp_1_ds_28645 select /*+ no_parallel(t) no_parallel_index(t) dbms_stats cursor_sharing_exact use_weak_name_resl dynamic_sampling(0) no_monitoring */"OBJECT_ID", "ARCHIVE_DATE", "WF_ID", "REC_TIME", rowid SYS_DS_ALIAS_0 from "EDIAPP"."CORRELATION_SET" sample ( .3482546807) t
Looking at the statistics above, it is clear that most of
the reads are consumed by statistics gatherer run by scheduler jobs which is
scheduled to run automatically in oracle 10g using DBMS_STATS.
The task is scheduled in WEEKNIGHT_WINDOW of the
DBA_SCHEDULER_WINDOWS which starts daily at 10 00 pm EST.
So in order to reduce this waits on db file sequential read,
its better we disable this scheduled job as we have statistics gathering
run explicitly.
Also init parameter db_file_multiblock_read_count
is currently set to 32. Oracle
recommends not setting this value manually and letting oracle choose the
optimal value. So we can make this alteration as a step to improve the
performance.
The other wait events log file sync and log file
parallel write are related to each other. By decreasing the log file sync
wait even, we can reduce log file parallel write wait event.
From dataguard perspective (as we have dataguard set up for this
environment),
For Data Guard with synchronous (SYNC) transport and commit
WAIT defaults, log file parallel write also includes the time for the
network write and the RFS/redo write to the standby redo logs. This makes us
clear that an improved network can improve the waits encountered.
Steps to improve the performance by eliminating the above
wait events is as follows.
- Tune
LGWR to get good throughput to disk . eg: Do not put redo logs on RAID 5. à
This is checked by Unix admin and made clear files are not in RAID 5
- If
there are lots of short duration transactions see if it is possible to
BATCH transactions together so there are fewer distinct COMMIT operations.
Each commit has to have it confirmed that the relevant REDO is on disk.
Although commits can be "piggybacked" by Oracle reducing the
overall number of commits by batching transactions can have a very
beneficial effect. à Apps team should take
this into account for improving performance and hence advised them the
same.
- See if any of the processing can use the COMMIT NOWAIT option (be sure to understand the semantics of this before using it). à This is not recommended though
- See if any activity can safely be done with NOLOGGING / UNRECOVERABLE options. à Compromises high availability and hence is not recommended as we have standby setup
- Check
to see if redologs are large enough. Enlarge the redologs so the logs
switch between 15 to 20 minutes. à
Current redo log size is 500 mb. We can increase this to 1gb so the log
switch takes increased time.
Action plan would be as follows.
- Disable scheduled jobs to collect statistics
- Change db_file_multiblock_read_count value
- Increase redo logs to 1gb
- Reduce log buffers from the current size
The above example may provide a good feed to your white
paper as this is the live tuning that has been recommended to application team
and this works well after reducing log buffers size. This resulted in decreased
log file sync.
The statistics were gathered for the database and indexes
(for the tables that were affected by the batch job) were rebuilt and the
performance is monitored again. This shows a very good increase in performance
by reduction of sequential read and scattered read. Application team is
satisfied with the performance which is the primary goal.
Thank you!! J Happy tuning!! JJ
Very useful Article .. Thank You dear :)
ReplyDeleteThank you for the appreciation!!
Deleteinteresting article.
ReplyDeleteQuick question. Was the AWR report generated for a single day (or) did u generate it for multiple days to review the impact pattern?
The AWR report was generated for good times and bad times the DB went through. Many reports were generated to compare the stats and I have shown the problematic report here on which the resolution steps have been attempted. Thank you!!
Deletegud job man really i was confused in reading the full awr report from net but this is awesome man..
ReplyDeleteThank you!! :)
Delete